Research
Graph Representation Learning
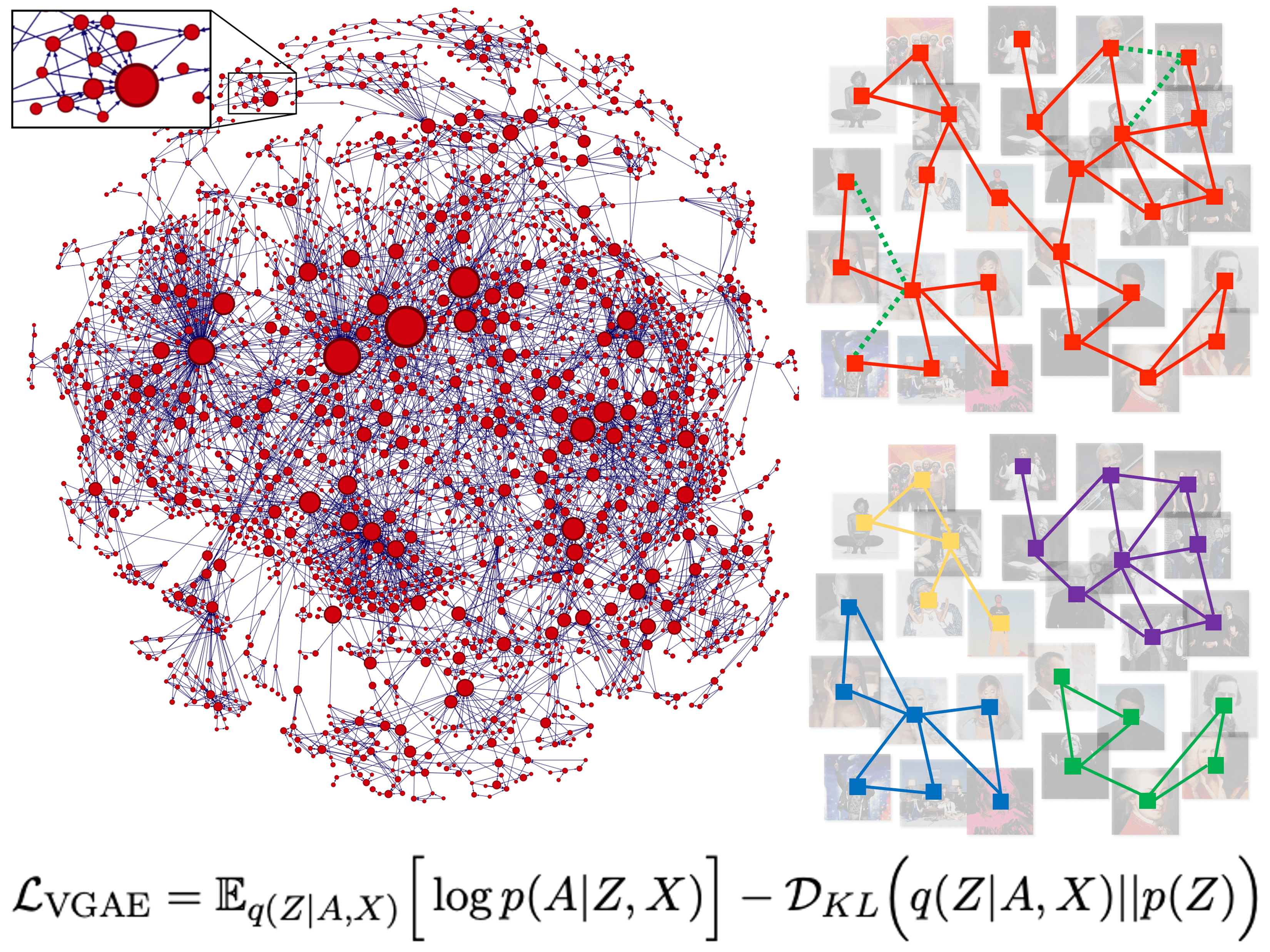
My primary research interest, initiated during my time at École Polytechnique, lies in the study of graphs. These structures are ubiquitous in domains such as web mining, social networks, and biology, owing to the proliferation of data that represent entities (or nodes) connected by links (or edges) capturing their relationships or interactions.
Extracting meaningful information from graphs is essential for solving a wide range of machine learning problems, including link prediction [1], community detection [2], and influence maximization [3]. My research in this context focuses on graph representation learning, which aims to automatically learn low-dimensional vector representations, also known as "embeddings", of nodes, edges, or entire (sub)graphs that capture and summarize key graph properties [4]. I am equally interested in the theoretical foundations of these representations and in how they can enable empirical advances across downstream tasks.
In particular, a significant portion of my research has focused on graph autoencoders (GAEs) and variational graph autoencoders (VGAEs), two powerful families of unsupervised graph neural networks for learning node embeddings [4]. While early GAEs and VGAEs showed promise, they faced limitations in scalability and structural flexibility, restricting their adoption in real-world scenarios. My research addressed these challenges by introducing architectural enhancements that extend their practical applicability: enabling scalability to graphs with millions of nodes [5, 6], adaptability to diverse topologies including dynamic and directed graphs [1, 4, 7], simplification of model architectures [8, 9, 10], and robustness across multiple graph learning tasks [2, 11]. These contributions help bridge the gap between the theoretical design of GAEs and VGAEs and their deployment in large-scale, real-world applications.
Recommender Systems
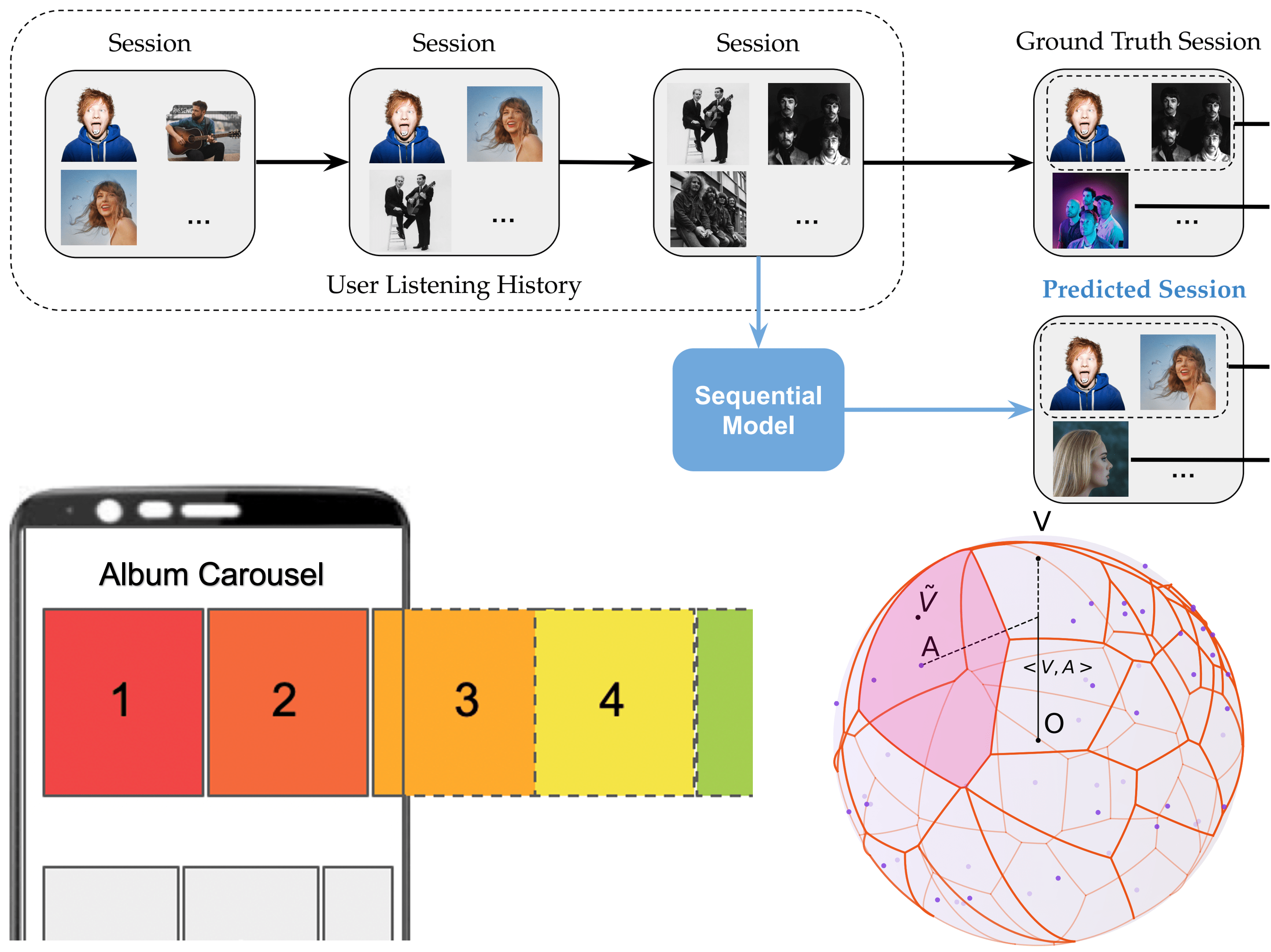
Another strong research interest of mine, particularly since my time at Deezer, centers on recommender systems. Online platforms such as music and video streaming services rely on recommendation algorithms to personalize user experiences by suggesting relevant content. They play a crucial role in helping users navigate large catalogs and facilitating the discovery of new content aligned with their preferences. Recommender systems are widely recognized as key drivers of user satisfaction and engagement [12].
I have explored various foundational research questions in this field, focusing on representation learning for users and recommendable items. Closely connected to my work on graphs, this includes graph-based recommendation problems. My research has established graph autoencoders as powerful tools for addressing core challenges such as recommending similar items that "fans also like" [7] and identifying item communities for joint recommendation [2, 4].
Beyond graph-based problems, I have also tackled a wide range of other challenges in recommendation, including:
- Cold start: recommending content for new users or items with little to no historical data [7, 12, 13];
- Sequential recommendation: leveraging Transformers [14, 15, 16, 17] and studying how to scale them [16], incorporate time-aware dynamics [14], and capture psychology-informed user behavior [17];
- Carousel personalization: optimizing ranked lists of recommended items using contextual bandits [13, 18];
- Collaborative metric learning: developing hierarchical latent relation models for improved performance [19];
- Theoretical analyses: examining whether our modeling assumptions actually make sense [20, 21, 22].
Across these directions, my work aims to advance the scalability, effectiveness, personalization, and trustworthiness of modern recommender systems, connecting theoretical insights with real-world applicability.
Large Language Models
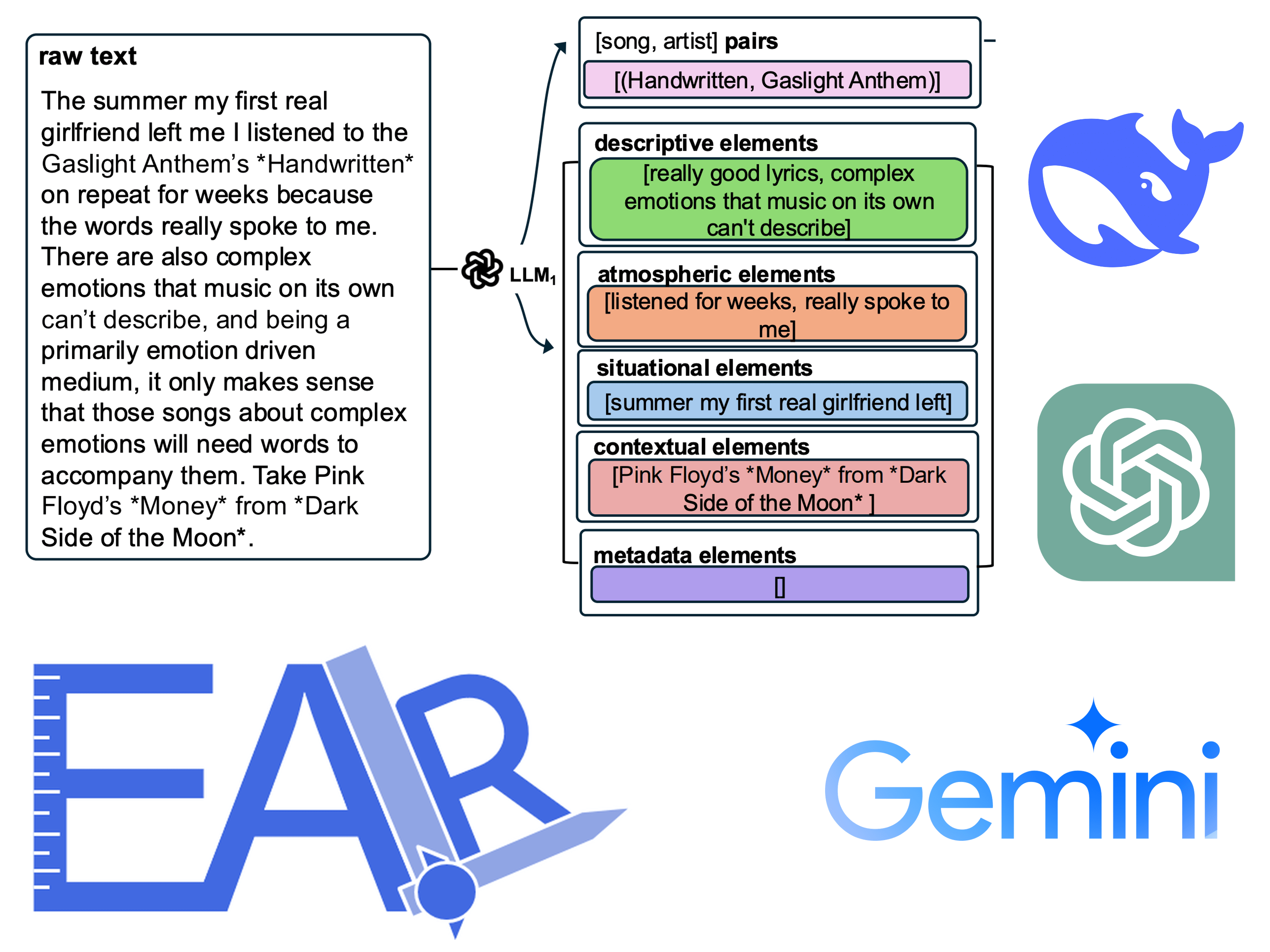
More recently, I have developed a growing interest in large language models (LLMs), which are deep learning models trained on vast textual corpora and capable of performing a wide range of language understanding and generation tasks. Emerging research highlights their strong potential to impact graph learning and recommender systems. I am personally involved in ongoing projects that benchmark LLMs for multimodal retrieval and recommendation [23].
However, the emergence of LLMs raises concerns around fairness, transparency, responsibility, and accountability. In finance, for example, graph-based models are often used to assess creditworthiness. While LLMs may enhance such systems, preventing discriminatory outcomes for clients with similar financial profiles is essential. In recommendation, the rising use of LLMs has sparked debate around the responsibilities of such systems. Concerns are growing about their ability to promote a fair and diverse cultural landscape when recommending content such as music or movies, and about the various biases they may introduce or reinforce.
I am currently contributing to new scientific projects that aim to address these challenges, with the broader goal of improving the trustworthiness of LLM-based systems in high-stakes applications. To support community debate and critical reflection, I am also co-organizing the second EARL workshop on Evaluating and Applying Recommender Systems with Large Language Models, co-located with the RecSys 2025 conference [24].
Applications to Music
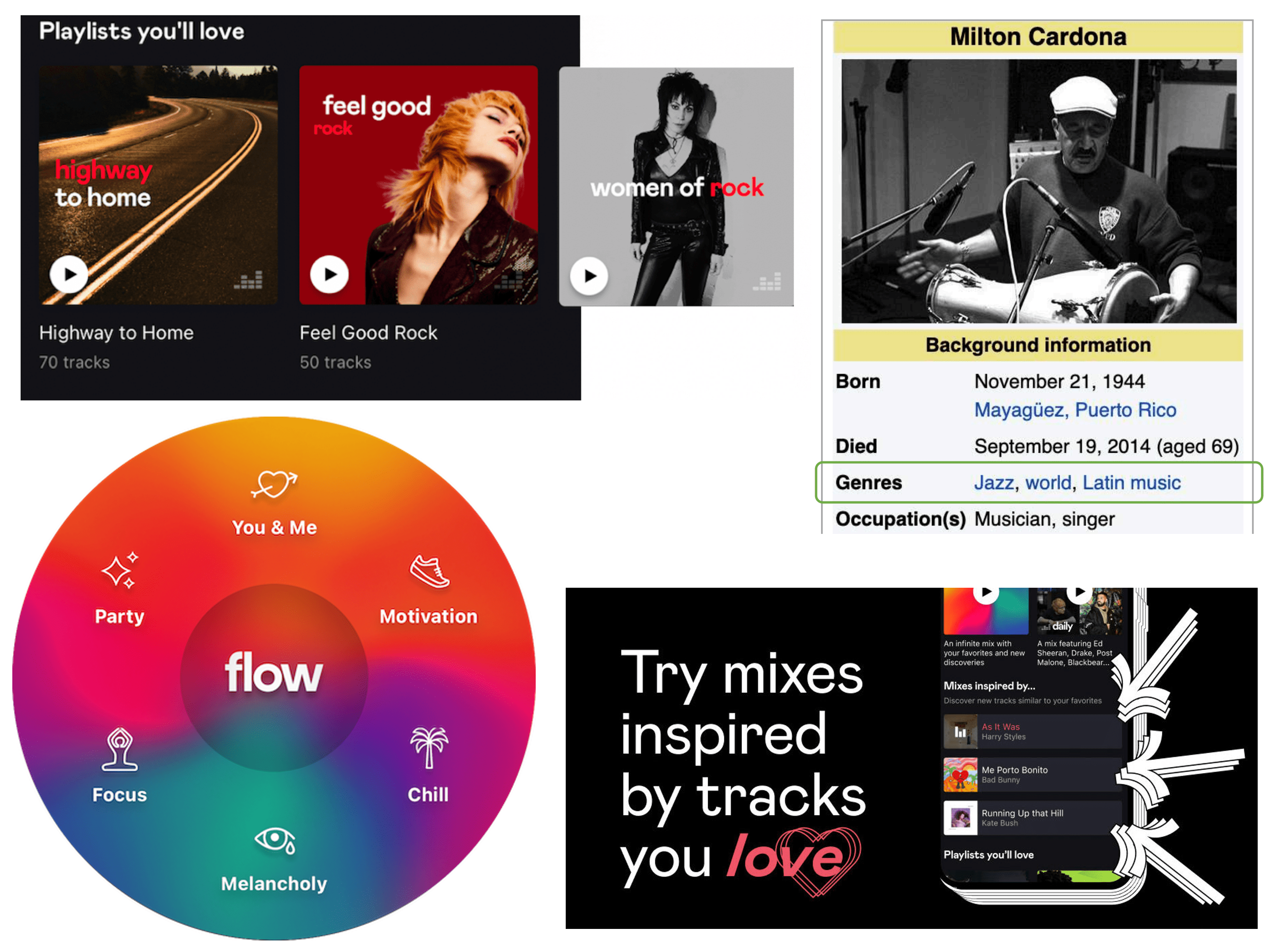
Music has been a natural and central application domain for my research, both due to personal interest and to my seven-year tenure at Deezer, a music streaming service. Many of the graph learning and recommendation projects mentioned earlier were evaluated on music-related data.
More broadly, I co-authored a significant share of the scientific papers describing the music recommender systems we A/B tested and deployed on Deezer between 2018 and 2024. These systems support music discovery for millions of users worldwide. This includes:
- Music carousels: dynamically filling carousels with recommended lists of playlists or albums [13, 18];
- New releases discovery: fostering the discoverability of new releases and emerging artists [13, 25];
- User onboarding: improving music recommendation quality for new users on the service [12];
- Flow moods: recommending music by mood through audio signal analysis and collaborative filtering [26];
- Track mix: generating mix playlists "inspired by" input music tracks, using a GPT model [15, 21];
- Playlist continuation: suggesting music tracks to extend user-generated playlists on the service [16].
I also contributed to exploratory studies on music, including modeling cultural perceptions of music genres [27, 28, 29] and analyzing the impact of recommender systems on local music promotion [30]. Several of these publications introduced private Deezer datasets, which we subsequently released to support reproducibility and scientific research.
I remain actively involved in music-related research and am also exploring new application domains. Stay tuned!
Acknowledgments
This research is the result of collaborative work with many talented colleagues and friends over the years. You will find most of them on my Google Scholar page.